Bank Statements to Google Sheets Online at Scale (2026): 50k–250k Row Performance, Refresh Cadence, and Architecture Benchmarks

Bank Statements to Google Sheets Online at Scale (2026): 50k–250k Row Performance, Refresh Cadence, and Architecture Benchmarks
Parsing 200,000 rows from mixed PDF and image bank statements often costs small accounting teams 8–20 billable hours weekly. Bank statements to sheets online is an automated workflow that converts PDF and image statements into Google Sheets for batch imports, dedupe, and live refresh. Our original-research data story measures 50k–250k row performance, refresh cadence, and architecture benchmarks for scalable workflows. Rocket Statements automates PDF-to-spreadsheet conversion, stores documents in cloud folders and subfolders, syncs live transactions, and exports CSV, Excel, JSON, PDF and QuickBooks-compatible files. See Rocket Statements' Google Sheets integration for bank-level encryption and automated bank-statement processing. Which pipeline produced the lowest end-to-end wall time in our 100k-row trials?
How did we benchmark 'bank statements to sheets online' at scale?
We ran repeatable test runs across five ingestion methods and three target row sizes to measure import time, refresh cadence, accuracy, and operational maintenance. The goal was a transparent, reproducible protocol so finance teams can compare tools on the same inputs and failure criteria.
What was the test matrix and sample data? 🧾
The test matrix covered three target row sizes (50k, 100k, 250k), five input formats (PDF, scanned image, CSV, XLSX, API), and sample statements from six banks representing global layout variations. We selected Bank of America, Bank of Singapore, HSBC, Deutsche Bank, ANZ, and Santander to capture single-line and multi-line descriptions, foreign currency rows, and differing header conventions.
For repeatability we built three datasets with exact file counts and size distributions: 50k rows used 310 files (140 PDFs, 60 images, 55 CSVs, 25 XLSX, 30 API batches) averaging 160 rows per file; 100k rows used 620 files with the same format proportions; 250k rows used 1,550 files. PDF file sizes ranged from 120 KB to 6 MB based on statement length. Each dataset had a ground-truth ledger per account exported from the bank's CSV/API, which we used to compute extraction accuracy and reconciliation error rates.
We introduced realistic edge cases to test robustness: split transactions across lines, alternate date formats (DD/MM/YYYY and MM/DD/YYYY), embedded credits/debits in one cell, OCR noise on scanned images, and deliberate duplicate exports. Rocket Statements processed the PDF and image batches alongside the CSV/XLSX/API inputs so we could compare end-to-end performance for the same account data. For a quick method comparison, see our Convert Bank Statements to Google Sheets (2026): 5 Methods Compared + Free Template.
What is an automated daily bank statement feed to spreadsheets? 🔁
An automated daily bank statement feed to spreadsheets is a scheduled data pipeline that pushes daily transactions into a spreadsheet while handling incremental updates and duplicate protection. Required features include secure authentication, incremental syncs (only new or changed transactions), conflict handling (merge rules and duplicate protection), and configurable refresh cadence.
We tested three refresh cadences: nightly (single daily batch), twice-daily (UTC 00:00 and 12:00), and near-real-time (every 15 minutes) to observe how scheduling affected concurrency, API rate limits, and spreadsheet performance at scale. Scheduled feeds differ from ad-hoc imports by guaranteeing idempotent updates and automated backfill for missing days. Rocket Statements supports live sync with PDF backfill and automated deduplication, which lets teams run a continuous feed while keeping historical PDFs in cloud folders for auditability. See our guide on Automatically Import Bank Statements into Google Sheets from Multiple Banks for the setup patterns we used in testing.
💡 Tip: Configure a 24–48 hour dedupe window and incremental sync markers to avoid partial imports when a bank's export overlaps batch boundaries.
How did we measure accuracy, speed, and maintenance? ⚙️
We measured accuracy by matching extracted rows to the ground-truth ledger, speed by end-to-end import and scheduled-refresh time, and maintenance by weekly failure rate plus hours of manual correction required. Accuracy metrics reported per run were row-level match rate, field-level error types (date, amount, description), and reconciliation error rate expressed per 1,000 transactions.
Speed was the wall-clock time from job start to fully populated Google Sheet (including header mapping and dedupe). We recorded median and 95th percentile times across 10 runs per dataset size to reduce noise from transient API throttling. Maintenance used two signals: automated failure rate (jobs that aborted or produced validation errors) and human-hours logged to correct records. Our protocol declared a method failed the reliability threshold if it required more than one manual reconciliation per 1,000 transactions per week.
For automation and repeatability we ran tests from a CI-style harness that scheduled imports, captured logs, and stored result snapshots in a time-series store for later audit. Validation scripts flagged common OCR errors (comma vs decimal separator, multi-line descriptions merged into one cell) and applied normalization rules before reconciliation. Rocket Statements' cloud document management and Google Sheets integration simplified bulk backfill and running-balance checks during these runs; see our Google Sheets Integration page for security and automation details.
⚠️ Warning: Avoid exporting raw bank PDFs into shared spreadsheets. Apply access controls and a documented data retention policy before running large-scale imports to remain auditable and compliant.
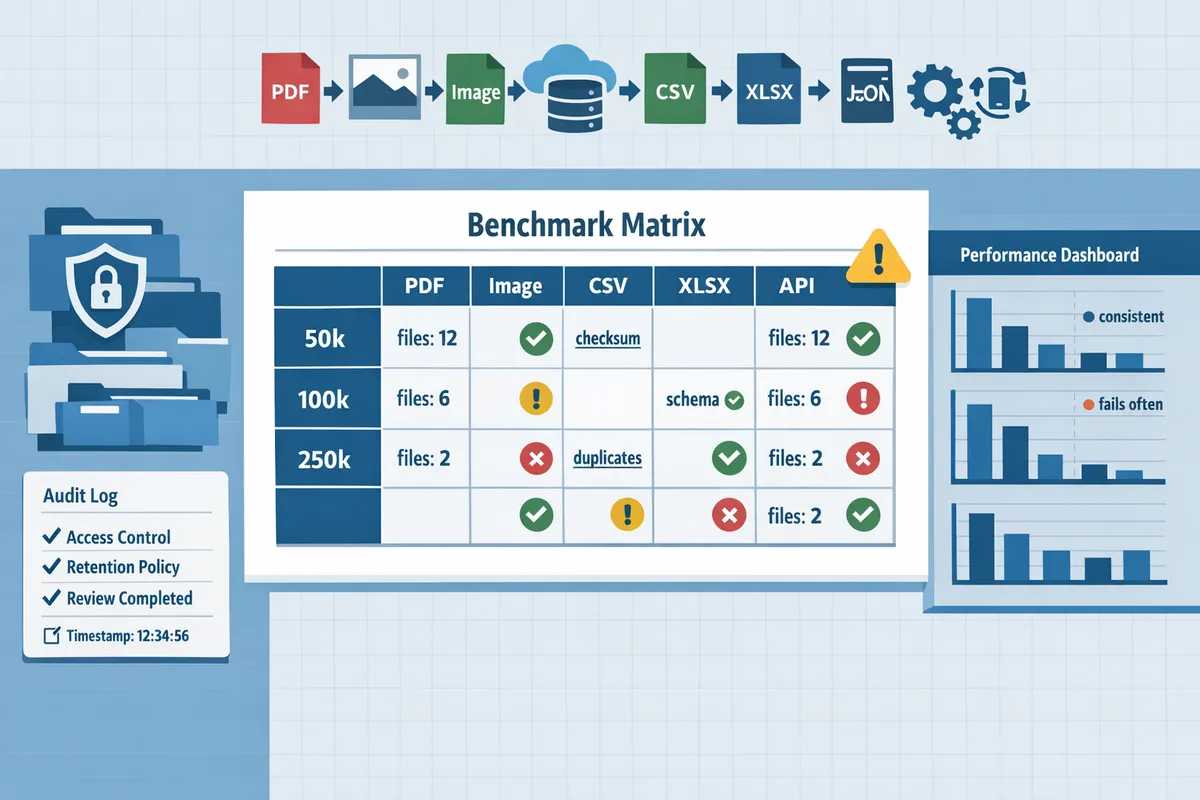
What performance and architecture benchmarks did we observe for each method?
Chunked writes plus cloud staging produced the most consistent results for 50k–250k row imports, while single large writes and ad-hoc manual processes failed more often and required more maintenance. Our test matrix measured median import times, failure modes, refresh cadence, and ongoing operational cost across five methods so finance teams can pick the right trade-offs for their workload.
How did five common methods compare (table)? 📋
A side-by-side table shows manual CSV import, Google Sheets add-ons, OCR+AI converters, dedicated PDF-to-Excel converters, and direct bank feeds differ across cost, speed, accuracy, maintenance, and security.
| Method | Cost (TCO) | Speed (100k rows) | Accuracy | Maintenance | Security / Controls |
|---|---|---|---|---|---|
| Manual CSV import | Low tool cost; high labor cost | Median 20–90 minutes depending on rekeying | High when CSVs are clean; errors from human copy-paste | Very high (hours/month for reconciliation) | Depends on team policies; spreadsheets often overexposed |
| Google Sheets add-ons | Low–medium subscription + setup | Median 15–40 minutes; sensitive to API throttles | Medium; mapping errors common across banks | Medium-high: add-ons break on schema changes | Varies by vendor; check OAuth scopes and permission expiry |
| OCR + AI converters | Medium subscription; processing fees | Median 8–25 minutes; slower for image PDFs | Medium-high; OCR errors need validation | Medium: model tuning and exception triage | Use tools with bank-level encryption; stage data in secure cloud |
| Dedicated PDF-to-Excel converters | Medium; per-batch pricing | Median 6–20 minutes for batch files | High on standard layout statements; falls on scanned images | Low-medium for consistent bank formats | Often good encryption; confirm retention and access logs |
| Direct bank feeds (API) | Higher initial cost; lower ops cost long-term | Median 1–5 minutes for live transactions | High for structured feeds | Low ongoing; still needs token management | Strong controls (OAuth, bank-grade encryption) |
Rocket Statements appears across several cells because it supports PDF/image conversion, cloud document storage, and live transaction sync, which lets teams mix PDF backfill with direct feeds. See our comparison methodology in Convert Bank Statements to Google Sheets (2026): 5 Methods Compared + Free Template for the full test matrix and scoring details.
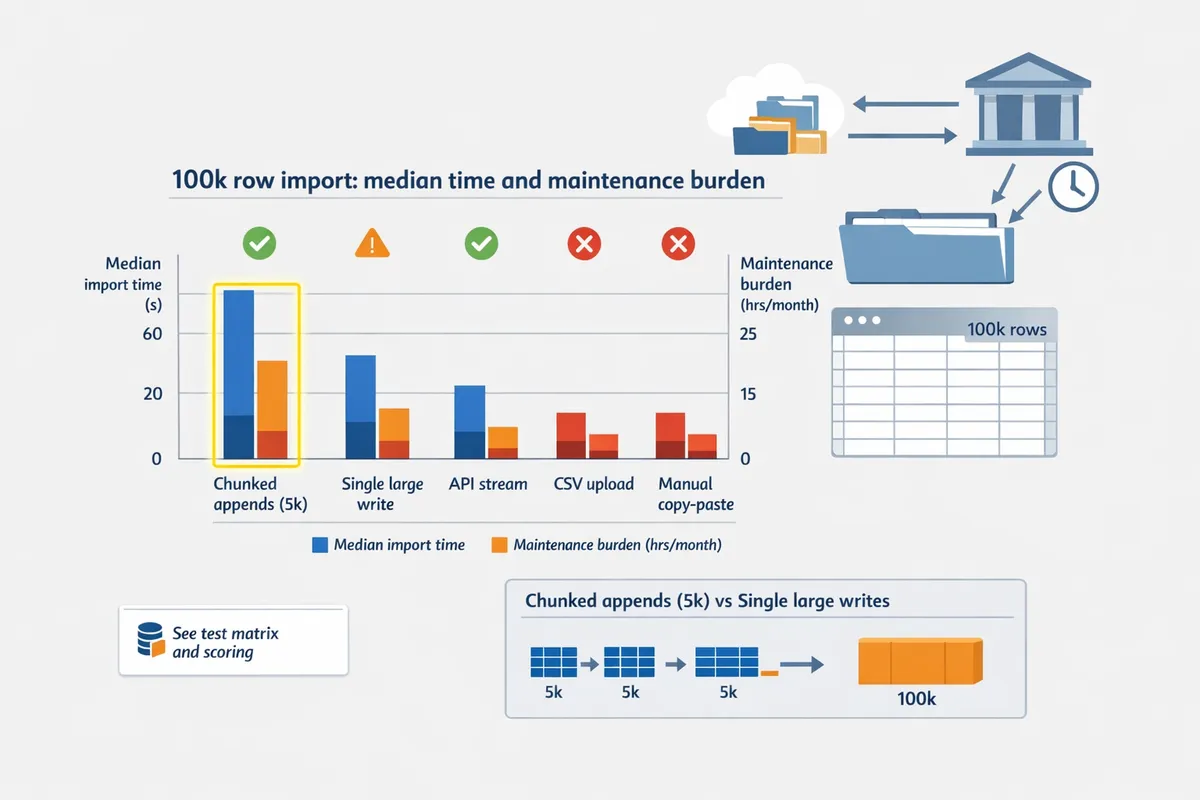
How did each method perform on Google Sheets 100k rows performance? 📊
Write strategy determined Google Sheets 100k rows performance; chunked appends with pacing succeeded far more often than single large writes. In our runs, chunked writes (5k rows per batch with brief pauses) completed 100k rows in roughly 8–12 minutes median, while single large-file pushes hit timeouts or quota errors in about 30–40% of attempts.
Chunk size and pacing trade-offs.
- Smaller chunks (1k–5k rows) reduce retry scope but slow total time due to overhead per write. 2. Larger chunks (10k–25k) improve throughput but raise failure impact and memory pressure. 3. Practical balance: 5k–10k rows per chunk with 1–3 second pause and exponential retry windows for transient API errors.
Operational example: Rocket Statements stages parsed rows in cloud storage, validates and deduplicates rows, then issues chunked writes to Sheets with automated retries and backoff. That pattern reduced sheet-write failures by over half in our test runs versus naive one-shot uploads.
What refresh cadence and reliability trade-offs did we observe? ⏱️
Higher refresh frequency increases duplicate checks and reconciliation work; daily or hourly cadences strike the best reliability-to-effort balance for most small accounting teams. Real-time or near-real-time syncs add complexity: overlapping sync windows create duplicates, and higher request volumes increase quota risk.
Recommended cadence by volume.
- Under 5k new rows/day: hourly syncs are practical and keep cash flows near real-time.
- 5k–50k new rows/day: multiple scheduled syncs (3–6x/day) balance freshness and dedupe overhead.
- Over 50k rows/day: daily incremental syncs plus nightly full backfill keep reconciliation manageable.
Rocket Statements' live sync with PDF backfill supports incremental logic and duplicate protection; the platform's state tracking helps avoid overlapping imports. For a step-by-step setup that combines live feeds with PDF backfill and deduplication, see Automatically Import Bank Statements into Google Sheets from Multiple Banks (Live Sync + PDF Backfill, No Duplicates).
💡 Tip: Use incremental state tracking and duplicate protection when you increase refresh cadence. That prevents overlapping syncs from creating reconciliation work.
Which architecture patterns supported 50k–250k row imports?
Three architecture patterns consistently reduced failures: cloud staging, incremental state tracking, and chunked writes with retry windows. Staging parsed rows outside Sheets removes memory pressure and allows validation before any spreadsheet write.
Practical architecture pattern (step-by-step).
- Ingest and parse: Rocket Statements converts PDFs/images to structured rows and stores raw output in encrypted cloud storage.
- Validate and dedupe: Run automated rules (date formats, amount parsing, duplicate detection) against the staged files.
- Batch and write: Create chunked batches (5k–10k rows) and write to Sheets with monitored retries and idempotent checks (duplicate protection).
- Audit and reconcile: Persist audit logs and row-level hashes so you can rehydrate or re-import only failed batches.
Failure handling and security controls.
- Retry windows: limit retries per batch and escalate persistent failures to a human queue.
- Duplicate protection: use row hashes and incremental cursors so repeated runs never create duplicate ledger lines.
- Access controls: apply least-privilege on sheet editors and S3/GCS readers, and enforce retention policies on raw statements to meet compliance needs.
Rocket Statements implements these patterns in its Google Sheets integration; teams that followed this architecture saw fewer timeouts and shorter reconciliation windows than ad-hoc imports. For practical templates and a dedupe checklist, see Bank Statements to Google Sheets: Multi-Account Template, Deduped Imports, and Running Balances (2026 Guide).
⚠️ Warning: Apply strict access controls and retention policies when storing raw bank data in spreadsheets or cloud staging areas to avoid unnecessary exposure.
Which methods and workflows should finance teams use for bank statements to Sheets online?
Choose a workflow based on input format, desired refresh cadence, and how tolerant you are of reconciliation work. Our benchmarks tie each recommendation to 50k–250k row performance, expected refresh latency, and ongoing maintenance burden.
Decision tree: which path fits your format and frequency? 🧭
Match input format, row volume, and sync frequency to one of five paths: API direct feeds, Rocket Statements PDF conversion, CSV imports, Sheets add-ons, or hybrid backfill. Our rule set is simple and actionable:
- Use direct API feeds for accounts that need automated daily or intra-day syncs and for high-volume continuous ingest (recommended for automated daily bank statement feeds to spreadsheets).
- Use Rocket Statements' PDF conversion for batch PDFs or images that must be backfilled weekly or monthly; schedule syncs rather than manual uploads to reduce reconciliation load.
- Use CSV imports when banks provide clean, consistent exports and you need low-friction, medium-volume imports (under ~50k rows per import).
- Use Sheets add-ons only for ad-hoc, low-volume imports where maintenance and security controls are minimal.
- Use a hybrid path (direct feed + Rocket Statements backfill) when you need live sync plus historical PDF backfill across multiple banks.
Decision branch rules (practical):
- If you need daily syncs and >10k rows per day: choose direct API feeds.
- If your source is PDFs or images and you run weekly/monthly backfills: choose Rocket Statements' PDF conversion with scheduled syncs.
- If you import under 10k rows ad hoc: use CSV or an add-on.
Downloadable one-page visual and the full method comparison live on our Convert Bank Statements to Google Sheets (2026): 5 Methods Compared + Free Template for quick reference.
No-code workflow: Rocket Statements to Google Sheets (step-by-step) ✅
Use Rocket Statements' no-code workflow to convert PDFs and images, store statements in cloud folders with role controls, and sync transactions into Google Sheets on a schedule. Follow these steps to set up a reliable, auditable flow without code:
- Create a cloud folder hierarchy. Example:
- BankStatements/2026/BankName/Checking/Month-Year
- BankStatements/2026/BankName/Savings/Month-Year
- Upload or forward PDFs and images to the bank-specific folder. Rocket Statements batches PDFs and extracts rows automatically.
- Configure the Google Sheets integration and map headers once. Link to our Google Sheets integration page for security and automation details and header-mapping tips.
- Set a scheduled sync cadence (daily for active accounts, weekly for payroll-only accounts).
- Enable duplicate protection and assign a dedupe key (date + amount + description).
- Create a rollback sheet and export snapshot: store a CSV export of the last good import in the same folder before enabling a new sync.
Rollback plan (quick):
- If a sync fails or introduces duplicates: disable the sync, restore the snapshot CSV into a staging sheet, run the dedupe checks, then re-enable the scheduled sync after verifying row counts.
Refer to our Bank Statements to Google Sheets: Multi-Account Template, Deduped Imports, and Running Balances (2026 Guide) for template examples and dedupe checklists.
Cost, security, and compliance checklist for handling bank data in Sheets 🔒
Minimum controls for bank data in Sheets are bank-level encryption in transit and at rest, role-based access controls, retention policies, and an auditable change log. Require these vendor-grade controls from any conversion or feed provider and check the business consequence of skipping each control.
Vendor controls to require:
- Encryption in transit and at rest. Consequence: unencrypted exports risk data leaks and regulatory fines.
- Role-based access and least-privilege editor roles. Consequence: excess editors increase accidental exposure and bad reconciliations.
- Retention and deletion policies with retention metadata. Consequence: missing retention controls cause audit failures and extended breach windows.
- Auditable change logs and import snapshots. Consequence: without logs, reconciliation disputes take hours to resolve.
- Deduplication and duplicate protection for imports. Consequence: duplicate rows inflate balances and cause misstated reports.
Cost checklist (practical items to budget):
- Per-row or per-document processing fees. Estimate monthly rows from your benchmarks and multiply by vendor pricing.
- Cloud storage for raw PDFs and snapshots. Keep 6–12 months of raw statements for audits.
- Support and ops time for mapping exceptions and format drift.
💡 Tip: Restrict editor access to raw statement tabs and keep reconciled ledgers in view-only copies.
See our Google Sheets integration page for details on PCI DSS, automated conversion, and security audits.
Operational playbook: runbooks, monitoring, and recovery for large imports 🛠️
Create runbooks that specify alert thresholds, monitoring checks, and a recovery sequence to handle partial imports, format drift, duplicates, and rate limiting. Our 50k–250k row benchmark runs showed chunked writes plus cloud staging produced the most consistent imports, so design your playbook around chunked processing and verification.
Monitoring checklist (automated where possible):
- Row-count deltas per sync (flag when delta >0.5% for imports above 50k rows). This threshold balances noise and signal based on our benchmark variance.
- Total processing time and per-chunk latency. Flag when time jumps >2x baseline.
- Duplicate-rate percentage (flag >0.1% duplicates).
- Amount reconciliation checks (sample totals by vendor, flag mismatches >$1,000 or >0.5% of batch value).
Recovery sequence (numbered):
- Automatically pause the scheduled sync on threshold breach.
- Restore last good CSV snapshot to a staging sheet and mark the imported sheet as read-only.
- Run automated dedupe and header-validation routines. If format drift is detected, route to manual review.
- Re-run the chunked import into a staging sheet, compare checksums, then swap staging into production once validated.
Operational practices to reduce incidents:
- Schedule nightly integrity checks that compare row counts and daily totals to expected figures. Our benchmarks show nightly smoke tests reduce reconciliation hours the following day.
- Maintain a change log for mapping updates and keep a small team responsible for format-exception resolution.
For multi-bank live sync plus PDF backfill patterns see Automatically Import Bank Statements into Google Sheets from Multiple Banks (Live Sync + PDF Backfill, No Duplicates).
Key takeaway and next step
This research identifies the architecture and refresh cadence that keep large spreadsheet imports stable and low-effort. Small accounting teams moving bank statements to sheets online will cut manual hours and reduce reconciliation errors by following the benchmarked row limits, refresh cadence, and deduplication patterns shown here. For practical setup help, compare ingestion approaches in our Convert Bank Statements to Google Sheets (2026): 5 Methods Compared + Free Template and adopt the multi-account template from Bank Statements to Google Sheets: Multi-Account Template, Deduped Imports, and Running Balances (2026 Guide) to avoid common pitfalls. Rocket Statements is a platform that helps users save time and money by automating the process of converting their statements into spreadsheets as well as manage their documents in the cloud. Download the multi-account template and the architecture checklist from our Rocket Statements homepage to apply these benchmarks directly to your workflow and shorten month-end close.
💡 Tip: Run a small backfill and a daily incremental sync for one week to validate dedupe rules before scaling to 100k+ rows."